
Отбор в данных: почему это вообще проблема
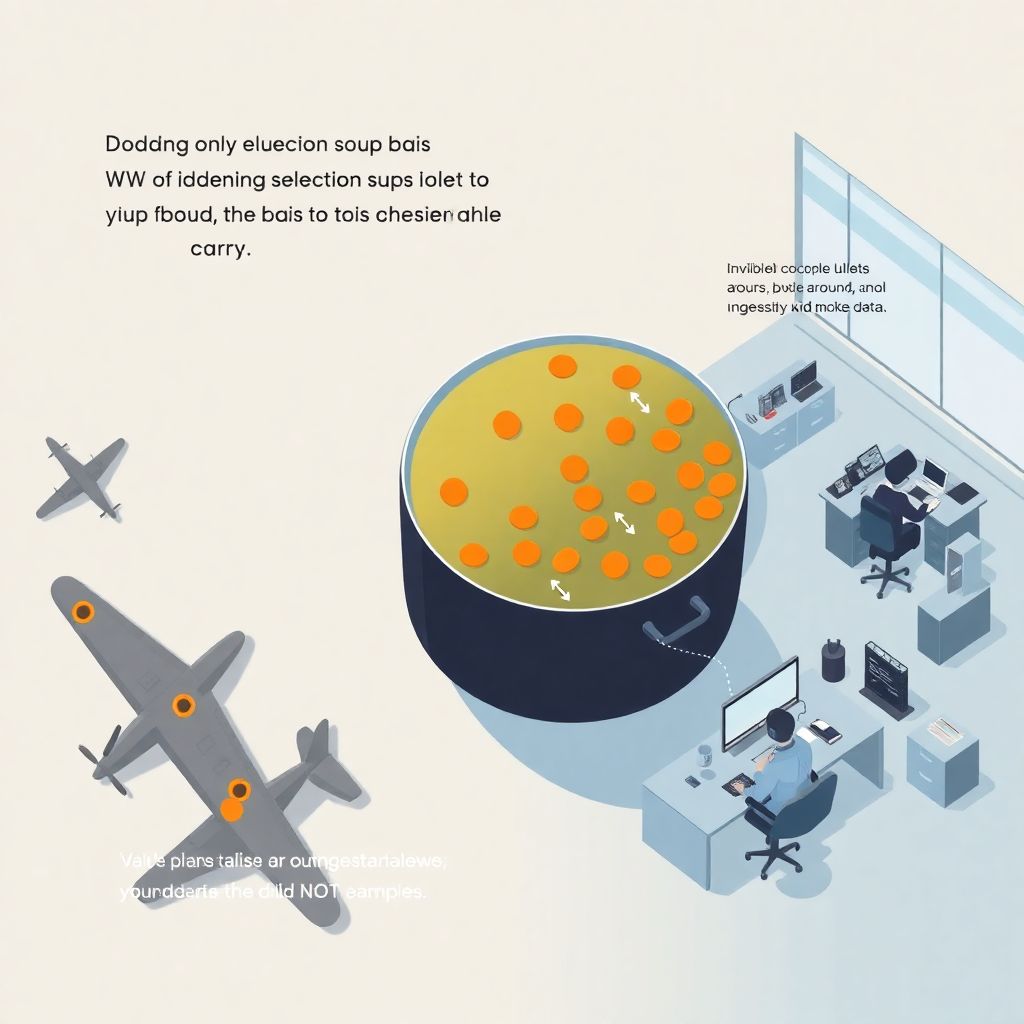
Представьте, что вы судите о вкусе супа, пробуя только морковку с поверхности. Формально вы «проанализировали суп», но выводы получатся странные. С данными происходит то же самое: вы видите только часть реальности, а потом честно строите графики, модели и делают выводы — хотя уже на этапе отбора что‑то пошло не так.
Вот это «что‑то» и называется отбором (selection). Мы берём не все наблюдения, а только те, что «дожили» до базы данных, соответствуют фильтрам, доехали до анкет, попали в лог событий. И если вы хотите не просто запускать ноутбук и писать код, а понимать, что делаете, — анализ отбора в реальных данных становится обязательным шагом, а не факультативом «для перфекционистов».
Короткая историческая справка: как люди вообще до этого додумались
Пули, самолёты и невидимые дыры
Один из классических примеров — история с анализом повреждений самолётов во время Второй мировой. Статистик Абрахам Вальд рассматривал, куда чаще всего попадали пули в возвращающихся самолётах, и военные хотели усилить броню именно в этих местах. Логично? На первый взгляд — да.
Но Вальд заметил: в выборке только самолёты, которые вернулись. Те, что получали критические попадания, просто не попадали в данные. Поэтому усиливать броню надо там, где дырок нет — потому что попадание туда означало, что самолёт не долетел до базы. Это был отличный пример смещения отбора, которое меняет картину мира.
От элитной математики к инструменту новичка
Долгое время такие эффекты считались чем‑то «академическим». Но по мере того как данные стали появляться буквально во всех сферах — от маркетинга и продуктовой аналитики до медицины и образования — то, как вы отбираете данные, стало важнее, чем сама модель. Сейчас даже простые курсы анализа данных для начинающих стараются включать темы про отбор, фильтры и смещения, хотя ещё 10–15 лет назад это было скорее «для продвинутых».
Онлайн‑мир ускорил процесс. Массовое обучение статистике и анализу реальных данных онлайн привело к тому, что студенты быстро учатся запускать алгоритмы, но часто не умеют задать один простой вопрос: «А кого я вообще анализирую?»
Базовые принципы анализа отбора, но по‑человечески
Шаг 1. Сначала отвечаем на вопрос «Кого здесь нет?»
Первый нестандартный приём — начинать не с того, что у вас есть в датасете, а с того, чего там не хватает. Это звучит странно, но сильно прокачивает мышление.
Задайте себе серию вопросов и честно попробуйте на них ответить:
— Кто мог бы сюда попасть, но не попал?
— Кого «отсеивают» технические ограничения: устройства, скорость интернета, платёжные системы?
— Какие группы людей заведомо недопредставлены (например, пенсионеры в онлайн‑опросах)?
Попробуйте буквально нарисовать на листе: круг «все, кто нас интересует» и вложенный в него круг «те, кто есть в данных». Разница между кругами — это ваша зона риска.
Шаг 2. Карта «пути события»
Данные обычно проходят путь:
человек → действие → система → логика сбора → фильтры → датафрейм.
На каждом шаге что‑то может потеряться. Полезная привычка — проговаривать этот путь, как рассказ другу:
— что человек должен сделать, чтобы попадание в данные вообще стало возможным;
— какие шаги отбрасывают часть людей (отмена подписки, не дошёл до анкеты, не нажал «согласен» и т.п.);
— какие фильтры вы применяете уже в коде (даты, страны, «активные пользователи», «валидные заказы» и т.п.).
Это намного полезнее, чем сразу лезть в Jupyter и строить графики.
Шаг 3. Отбор как гипотеза, а не как «фоновый шум»
Новичок часто думает: «Отбор — это просто ограничение по условиям, типа date >= ‘2024‑01‑01’». На самом деле каждый фильтр — это гипотеза вида: «Мне достаточно анализировать только этих людей, и выводы останутся справедливыми».
Попробуйте относиться к фильтрам так же серьёзно, как к выбору модели. Вы же не берёте первую попавшуюся нейросеть «потому что модно»? С фильтрами такая же логика: каждый из них должен быть обоснован и проверен хотя бы на интуитивном уровне.
Нестандартные приёмы: как проверять отбор без сложной математики
Метод «зеркала»: сравниваем с внешним миром
Очень практичный и недооценённый приём — сравнение вашей выборки с «зеркалом» снаружи:
— официальная статистика (Росстат, открытые данные министерств);
— отчёты крупных исследовательских компаний;
— агрегированные данные партнёров или платформ.
Например, если у вас в продукте 80% пользователей — мужчины 20–30 лет, а по стране в этом сегменте их заметно меньше, это уже сигнал: ваш датасет не отражает общую реальность, и все выводы будут «подкручены» под эту группу.
Метод «границ»: смотрим, кто живёт на краях
Попробуйте такой эксперимент:
для каждого фильтра (например, «активные пользователи за 30 дней») посмотрите:
— кто едва‑едва попал в выборку;
— кто чуть‑чуть не дотянул (например, активен 29 дней из 30).
Это «пограничные» пользователи. Если они сильно отличаются от основной массы (по возрасту, странам, устройствам, поведению), то ваш фильтр создаёт смещение. Иногда достаточно добавить или убрать пару дней в определении «активности», и картинка мира меняется.
Метод «сломанного фильтра»
Нестандартный, но очень полезный трюк: временно сломайте свои фильтры.
— Уберите часть условий и посмотрите, как меняются средние, медианы, доли.
— Попробуйте включить в выборку «подозрительных» пользователей, которых обычно отсекаете.
— Сделайте две параллельные выборки — «жёстко отфильтрованную» и «почти сырую» — и сравните результаты.
Если метрики ведут себя резко по‑разному, у вас не просто технический отбор, а сильное систематическое смещение. Это повод перепроверить всю логику сегментации.
Примеры реализации на практике
Пример 1. Аналитика продукта: активные vs молчащие
Допустим, вы анализируете мобильное приложение и считаете retention только по тем, кто зашёл хотя бы 3 раза за неделю. В отчёте всё красиво: пользователи активно возвращаются, метрики радуют менеджмент.
Но попробуйте сделать параллельный расчёт:
— retention по всем, кто вообще установил приложение;
— отдельный расчёт по «однодневкам»;
— и только потом — по «активным» пользователям.
Обычно оказывается, что львиная доля установок отваливается после первого запуска, но они «вычищены» отбором. В итоге реальная картина лояльности куда хуже. Такой простой шаг легко встроить даже в курс по анализу выборки и статистическим методам с нуля, и он уже учит думать критически.
Пример 2. Маркетинг и невидимые клиенты
Представьте, что маркетолог анализирует эффективность рекламных кампаний только по покупателям, которые дошли до оплаты онлайн. Красиво, удобно, данные лежат в одном хранилище.
Однако:
— часть людей бросает корзину и покупает офлайн;
— некоторые оформляют заказ по телефону;
— кто‑то получает товар по корпоративному договору и не проходит через стандартный путь.
Если эти потоки сильно отличаются по возрасту, городам или среднему чеку, то ваша «эффективность кампаний» — это по сути эффективность для узкой группы, а не для всей аудитории.
Пример 3. Учебные проекты и «сдвинутая реальность»
Многие учебные датасеты (особенно в формате «онлайн школа data analysis для новичков с сертификатом») подчищены и отобраны заранее: убраны пропуски, экстримы, странные пользователи. Это удобно для обучения, но формирует ложное ощущение, что «в реальных проектах примерно так же».
Полезная нестандартная практика для преподавателей:
давать студентам сначала «грязный» датасет с реальными проблемами отбора, а уже потом аккуратную версию. И предложить самим сформулировать, какие решения они приняли, а кого и почему отрезали. Это намного честнее, чем просто «порешать задачки».
Как встроить анализ отбора в свой рабочий процесс
Мини‑чеклист перед каждым анализом
Чтобы не усложнять жизнь, держите небольшой набор вопросов, который вы задаёте себе перед запуском ноутбука:
— Кто считаетcя «единицей анализа»? (пользователь, заказ, сессия, день)
— По каким правилам эта единица попадает в данные?
— Как я ограничиваю дату, географию, устройства, язык, статус аккаунта?
— Кто заведомо не попадает в данные, но может быть важен для вывода?
Если вы на какой‑то вопрос не можете ответить — это не повод бросать анализ. Это сигнал зафиксировать допущения: «Мы анализируем только тех, кто…» и честно проговорить это в выводах.
Автоматизация подозрительности
Небольшой лайфхак для тех, кто идёт в практический курс по анализу данных в Python для начинающих:
сделайте себе функцию‑шаблон, которая при загрузке датасета автоматически:
— выводит распределение по ключевым полям (страна, возраст, устройство);
— сравнивает их с предыдущими запусками анализа;
— подсвечивает резкие перекосы (например, внезапный рост доли одной страны до 80%).
Такой простой инструмент помогает автоматически ловить странности, связанные с отбором: например, вам внезапно начали залетать только мобильные пользователи, а вы продолжаете считать какие‑то метрики «в среднем по больнице».
Частые заблуждения новичков
«У меня же большая выборка, значит всё норм»
Большой объём не спасает от смещения. Можно иметь миллион наблюдений о пользователях с айфонами и ноль — о пользователях с бюджетными Android‑устройствами, а потом удивляться, почему продукт «в реальности» не работает так, как по отчётам.
Голос громкой, но однобокой выборки всегда звучит очень убедительно, и именно поэтому он опасен.
«Главное — вычистить аномалии, а отбор потом»
Новички часто сначала выкидывают «подозрительных» пользователей, а потом начинают думать про репрезентативность. Логика должна быть обратной: сначала вы понимаете, кого вообще хотите анализировать, а уже потом определяете, кто в этой группе выглядит аномально.
Иначе есть риск выкинуть как «аномалию» именно тех, кого в реальности больше всего, просто они не похожи на «удобных» пользователей из учебных примеров.
«Мы же учились, всё это рассказывали на курсе»

Даже если вы прошли отличное обучение и крутые курсы, типа обучения статистике и анализу реальных данных онлайн или любой модный курс по анализу выборки и статистическим методам с нуля, знание про отбор легко «теряется» в реальной работе. Почему? Потому что нет привычки проговаривать его вслух и включать в отчёты.
Сделайте простое правило: каждый раз, когда вы показываете результат, у вас есть отдельный абзац «Кого мы здесь анализируем и кого не видим». Это дисциплинирует и вас, и заказчика анализа.
С чего начать новичку: практический план
Мини‑практика на любой задаче

Если вы только входите в профессию, не обязательно сразу искать чудесный онлайн курс или большую программу. Начните с трёх конкретных действий на своих учебных или рабочих задачах:
1. Всегда рисуйте схему пути данных от реального человека до строки в таблице.
2. Явно выписывайте, какие фильтры вы применили и кого они отсекают.
3. Делайте хотя бы одну «контрольную» выборку с более мягкими фильтрами и сравнивайте результаты.
Такой подход можно спокойно вписать и в самостоятельное обучение, и в формат «онлайн школа data analysis для новичков с сертификатом» — он не требует сложной математики, но сильно улучшает качество любых выводов.
Где потренироваться
Идеальная связка для новичка выглядит так:
— базовый курс по статистике и Python (любой, но с упором на реальные данные);
— учебные проекты с сырыми датасетами (опросы, логи, транзакции);
— практические разборы ошибок, где специально показывают, как неверный отбор ломает выводы.
Сильно помогает, если в курс встроены задания по сравнению разных выборок, а не только «подбору модели». Так знания перестают быть теорией и превращаются в привычку задавать критичные вопросы к данным.
Итоги: думайте не только о том, что попало в данные, но и о том, что потерялось по пути
Навык анализа отбора — это не про «сложную статистику для гениев». Это про здравый смысл, умение сомневаться и привычку спрашивать: «Кого я сейчас не вижу?»
Если вы с самого начала встроите эти вопросы в работу, любой ваш проект — будь то учебные задачи в рамках курсов анализа данных для начинающих или реальные задачи на работе — станет надёжнее. А ваши выводы перестанут зависеть от того, «какая морковка всплыла в супе», и начнут отражать реальность, а не её случайный срез.