
Зачем вообще разбираться в трафик‑атаках
Когда сайт или сервис начинает «падать» от наплыва запросов, новичок часто списывает всё на удачный маркетинг или «сервер слабый». На практике очень быстро выясняется, что это либо перегрузка из‑за пикового легитимного трафика, либо атака, в том числе DDoS. Разница принципиальная: перегрузку можно переждать, атаку — нужно гасить. Понимание механики трафик‑атак помогает не только выбрать адекватную защиту от ddos атак, но и грамотно спроектировать инфраструктуру так, чтобы она спокойно выдерживала всплески запросов, не превращая каждый рекламный запуск в аварийную смену.
Шаг 1. Разобраться, какие бывают трафик‑атаки
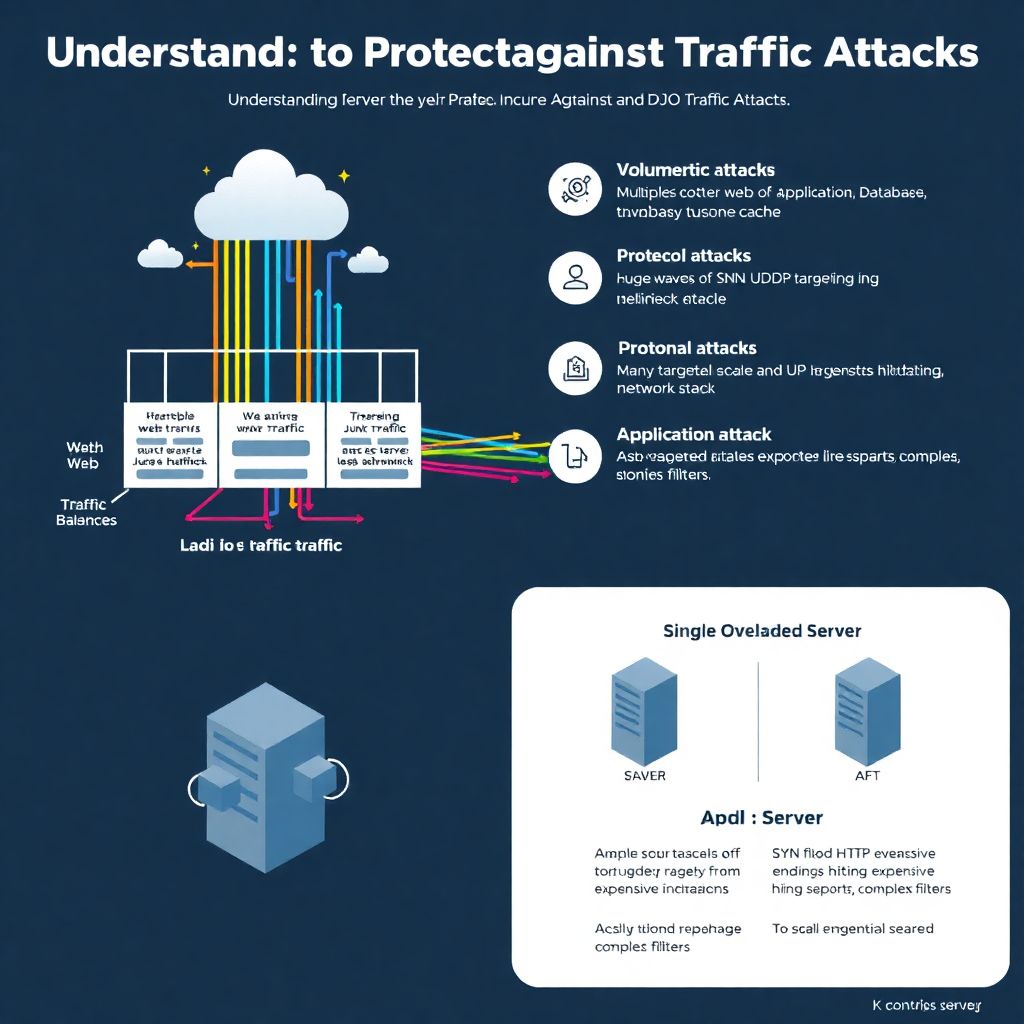
Для начала полезно классифицировать угрозы. Есть volumetric‑атаки, которые просто заливают канал гигабитами мусорного трафика, есть протокольные (SYN flood, UDP flood), выжимающие ресурсы сетевого стека, и есть application‑level удары по конкретным URL и API. Новички часто считают, что DDoS — это всегда гигантский поток пакетов, и игнорируют тихие, но очень эффективные запросы к «дорогим» операциям: поиску, отчётам, сложным фильтрам. Именно поэтому диагностика должна учитывать и сетевые метрики, и поведение приложений, а не ограничиваться только нагрузкой на канал и CPU.
Шаг 2. Спроектировать архитектуру под перегрузки
Прежде чем думать, где купить оборудование для защиты от сетевых атак, стоит посмотреть на собственную архитектуру. Частая ошибка — один мощный сервер «на все случаи жизни» без горизонтального масштабирования и балансировки. При всплеске трафика, даже легального, такой монолит ложится первым. Гораздо устойчивее модель с несколькими узлами, балансировщиками и отдельными слоями: веб, приложение, база данных, кеш. Новичкам важно сразу закладывать стейтлесс‑подход и возможность быстро добавлять инстансы. Тогда защита от атак превращается из паники в контролируемое расширение ресурсов и грамотную фильтрацию.
Шаг 3. Настроить базовые фильтры и rate limiting
Следующий шаг — убрать очевидный мусор на входе. Речь идёт о корректных ACL на уровне фаерволов, ограничениях по числу соединений с одного IP, защите критичных эндпоинтов и настройке WAF. Новички часто включают агрессивные правила «по умолчанию», ломая легальный трафик, и разочаровываются в средствах защиты. Правильный подход — постепенно ужесточать фильтры, регулярно смотреть логи и исключать легитимные паттерны. Для публичных API полезно вводить ключи, квоты и rate limits, чтобы одиночный клиент или скомпрометированный скрипт не мог забить все ресурсы даже без полноценной атаки.
Шаг 4. Вынести часть нагрузки наружу
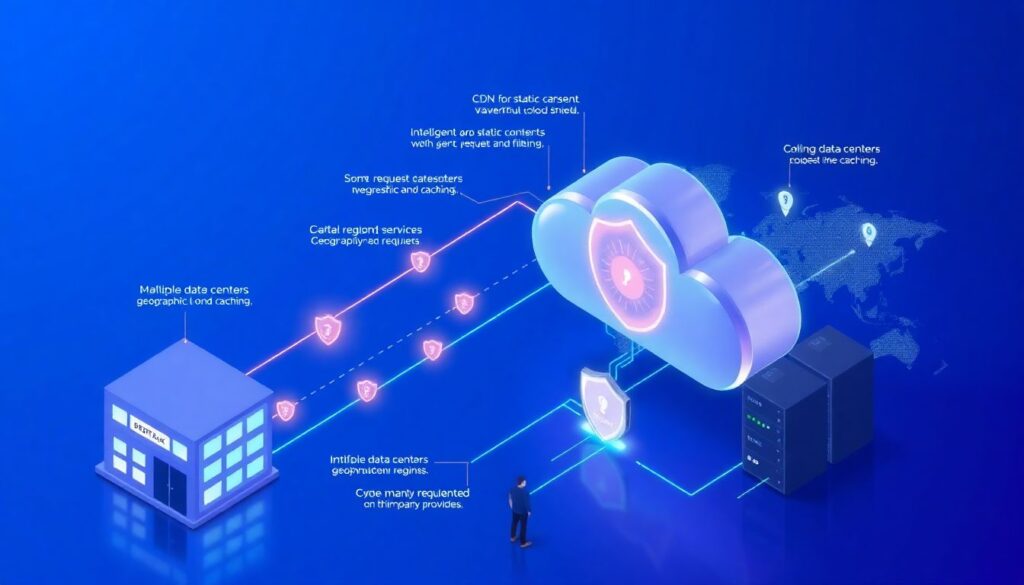
Когда собственные мощности ограничены, логично использовать облачную защиту от кибератак и перегрузки трафика. Речь не только о CDN для статики, но и о прокси‑сервисах с интеллектуальной фильтрацией запросов, географическим распределением и кэшированием. Новички иногда боятся «отдавать трафик третьей стороне» и держат всё у себя, хотя периметр уже давно вышел за рамки одного дата‑центра. Правильно подобранный провайдер позволяет выровнять пики, отфильтровать грубые атаки ещё до входа в вашу инфраструктуру и оставить локальным ресурсам только то, что действительно должно до них доходить.
Шаг 5. Подобрать сервис или решение под бюджет
Вопрос стоимости критичен, особенно для малого бизнеса. Довольно сложно сориентироваться, когда смотришь на ddos protection для бизнеса цена в разных провайдерах и видишь огромный разброс. Здесь важно трезво оценить свои RPS, критичность простоя и географию клиентов. Для небольших проектов часто достаточно базового уровня защиты у хостера или CDN‑платформы, а не максимального тарифа «на все случаи». Крупным системам нужен гибрид: внешняя фильтрация у провайдера и локальные средства для глубокой аналитики, корреляции событий и быстрой реакции на новые векторы атак.
Шаг 6. Настроить мониторинг и алерты

Даже самая продвинутая инфраструктура бесполезна, если вы узнаёте о проблеме от пользователей. Мониторинг должен фиксировать не только аптайм, но и аномалии по запросам, задержкам, ошибкам приложений и нестандартным паттернам трафика. Новички частенько ограничиваются парой графиков CPU и памяти, игнорируя сетевые показатели и логи веб‑сервера. В результате атака на уровне приложения выглядит как «что‑то тормозит». Грамотно настроенные алерты по ключевым метрикам позволяют заметить перегрузку на ранней стадии и включить сценарии реагирования до полного отказа сервиса.
Типичные ошибки новичков при защите от перегрузок

Большинство проблем в реальных инцидентах упирается не в нехватку железа, а в неверные решения. Часто встречается слепая вера в один инструмент: купили «железный» фаервол и считают, что все атаки остановятся у него. Или наоборот — поставили облачный сервис и перестали вообще смотреть свои логи. Другой популярный провал — отсутствие тестов: никто не моделирует нагрузку, не проводит учения, а первая настоящая атака превращается в хаос. Сюда же относится игнор резервирования: один балансировщик, один DNS, один канал — и всё держится на тонкой нитке без сценария отказа.
• Полагаться на «чудо‑устройство» как на единственное средство защиты
• Не проверять, что новые правила не ломают легальный трафик
• Не иметь плана действий на случай реальной атаки и не тренировать команду
Советы для тех, кто только начинает
Тем, кто впервые сталкивается с темой, стоит двигаться итеративно: сначала базовая гигиена (обновления, фаервол, простейший rate limiting), затем постепенное усиление за счёт внешних сервисов и оптимизации кода. Не фиксируйтесь на одном вендоре или технологии, проверяйте всё в бою с помощью нагрузочного тестирования. Если компетенций мало, разумнее взять услуги по защите сайта от перегрузок и атак у провайдера, чем пытаться за вечер освоить сложный стек. На старте ценнее не дорогие решения, а понимание того, как ведёт себя ваш сервис под стрессом и где у него реальные узкие места.
• Регулярно проводить нагрузочные тесты и обновлять сценарии
• Документировать инциденты и разбирать причины перегрузок
• Постепенно увеличивать уровень автоматизации, не забывая о ручном контроле
Когда нужно «железо», а когда — сервисы
Иногда без аппаратных решений не обойтись: крупные каналы, собственные стойки, строгие требования по контролю данных. В таких сценариях логично купить оборудование для защиты от сетевых атак, интегрировать его с существующими фаерволами и системами мониторинга. Но железо должно дополнять, а не заменять процессы и экспертизу. Для большинства онлайн‑проектов выгоднее комбинировать аппаратные и облачные компоненты, чтобы получить гибкую схему: внешняя фильтрация, внутренний анализ, автоматическое масштабирование и чётко прописанные процедуры реагирования.
Итог: выстраивать устойчивость, а не «гасить пожар»
Успешная защита — это не про волшебную коробку и не про один модный сервис. Это последовательное выстраивание устойчивой архитектуры, адекватный мониторинг и регулярные тренировки. Главное отличие опытных защитников от новичков в том, что первые заранее знают, как поведёт себя система при перегрузке, и что они будут делать по шагам. Чем раньше вы перестанете надеяться на случай и начнёте системно управлять трафиком, тем спокойнее пройдут и маркетинговые пики, и целевые атаки. Давление всё равно будет, задача — сделать так, чтобы именно ваша инфраструктура его выдерживала.